Projects
Course projects are marked with the course tag
Course projects are marked with the course tag

memsave_torchLowering PyTorch’s Memory Consumption for Selective Differentiation...
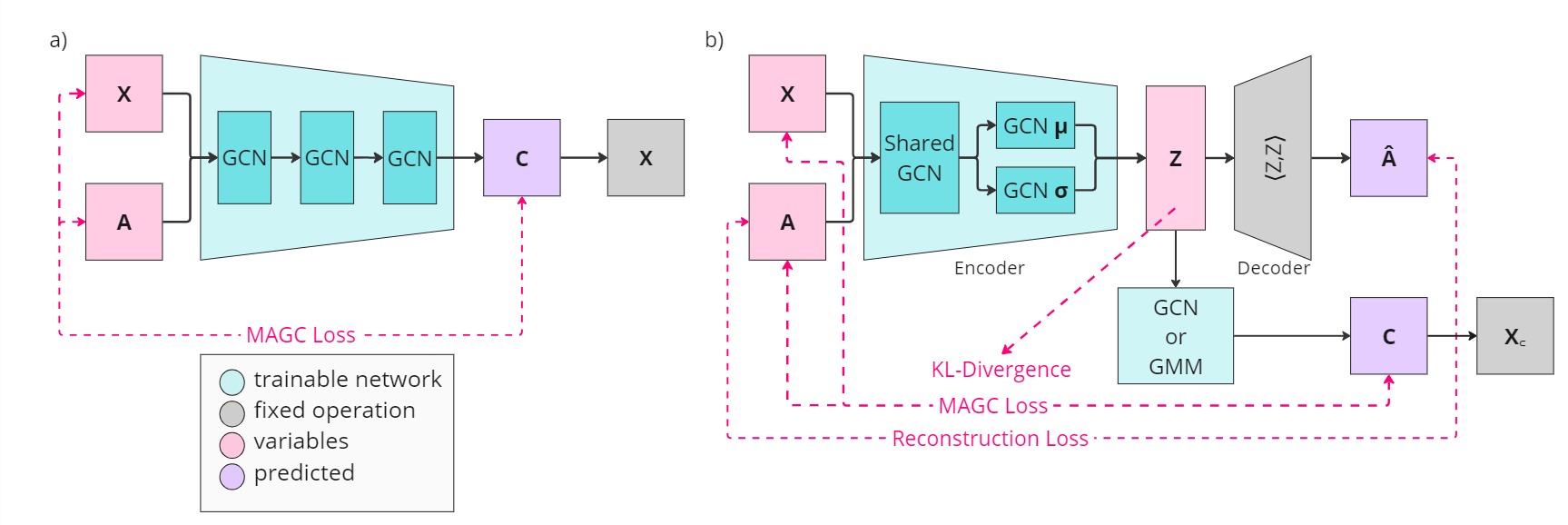
Modularity aided consistent attributed graph clustering via coarsening...
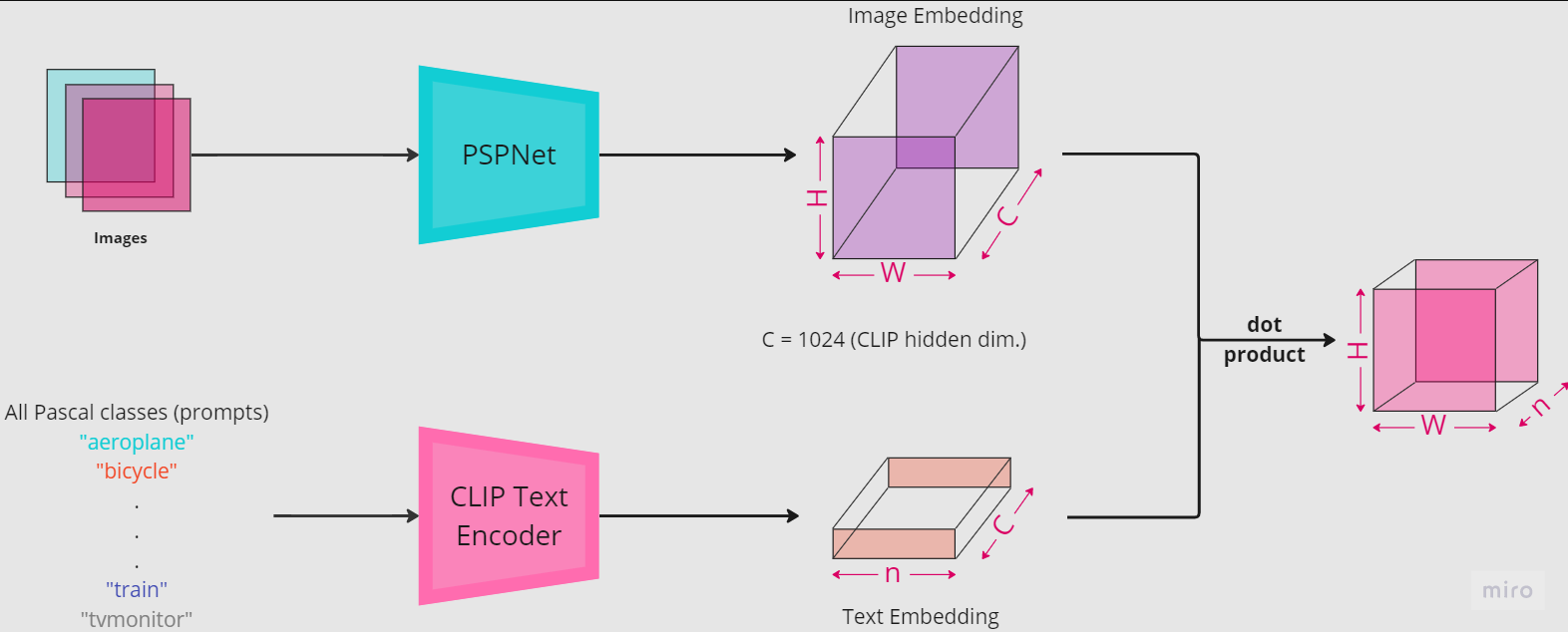
...