Zero-shot segmentation using large pre-trained language-image models like CLIP
In this project, we explored language-driven zero-shot semantic segmentation using large pre-trained language-vision classification models like CLIP.
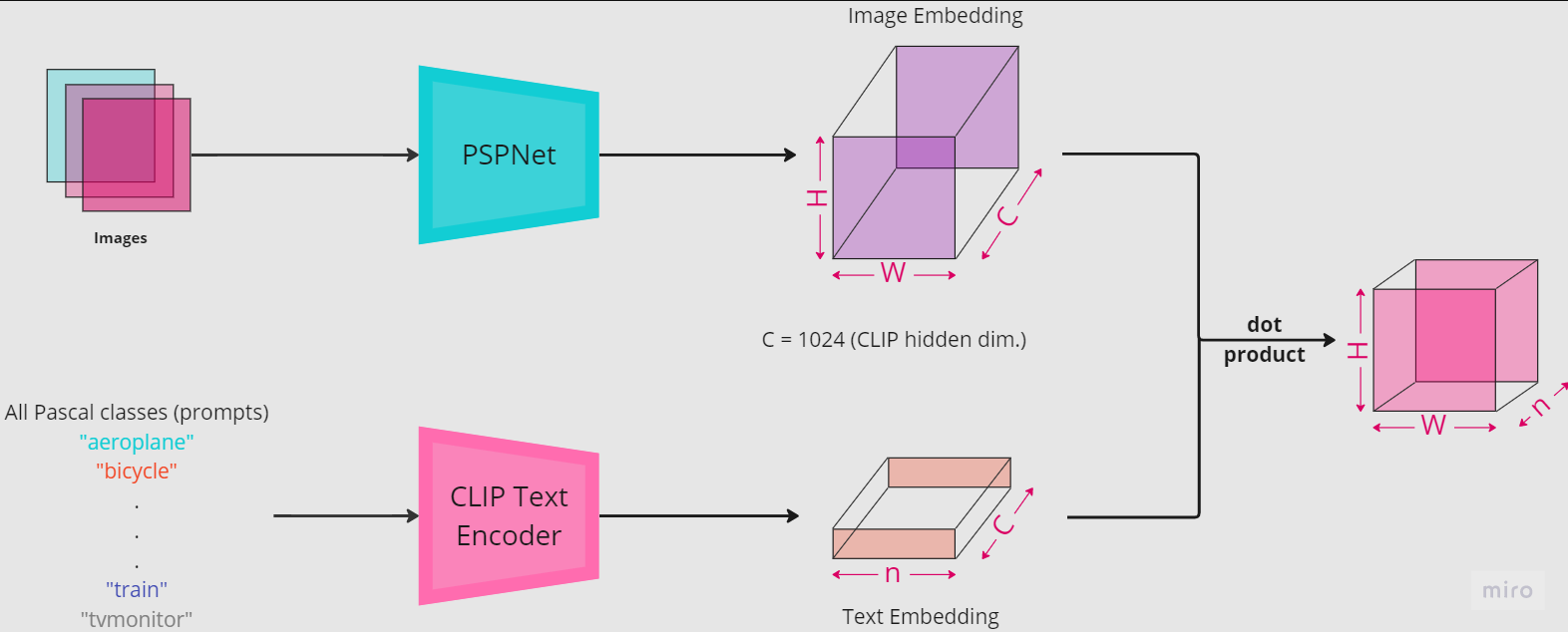
We made changes in the vision branch of CLIP, which includes architectures like ResNets and Vision Transformers (ViT) to be replaced with other segmentation based architectures like PSPNet, DeepLab, DPT.
We have used PSPNet along with CLIP’s text transformer (frozen). This gives us a good starting point for results. However, with just this, the segmentation maps are blobby and the boundaries are not well-defined, though the classes are in their correct approximate locations. This is because the image encoder is coarse and is tied to the text encoder’s embeddings (semantically) because of training. We can resolve this by adding PSPNet without removing the CLIP image encoder and using CLIP’s maps as pseudo-labels for training our segmentation model. We are testing out methods to improve this.
Summaries of some papers related to language-vision are available here: pdf, web-view.
The papers covered are:
- Open Vocabulary Scene Parsing 1
- CLIP (Learning Transferable Visual Models From Natural Language Supervision)2
- LSeg (Language-driven Semantic Segmentation)3
- RegionCLIP: Region-based Language-Image Pretraining4
- Open-Set Recognition: a Good Closed-Set Classifier is All You Need?5
- MaskCLIP (Extract Free Dense Labels from CLIP)6
References
Zhao, Hang et al. “Open Vocabulary Scene Parsing.” International Conference on Computer Vision (ICCV). 2017. ↩︎
Radford, Alec, et al. “Learning Transferable Visual Models From Natural Language Supervision.” ArXiv, 2021, /abs/2103.00020. ↩︎
Boyi Li, et al. “Language-driven Semantic Segmentation.” International Conference on Learning Representations. 2022. ↩︎
Zhong, Yiwu et al. “Regionclip: Region-based language-image pretraining.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. ↩︎
Sagar Vaze, et al. “Open-Set Recognition: a Good Closed-Set Classifier is All You Need?.” International Conference on Learning Representations. 2022. ↩︎
Zhou, Chong et al. “Extract Free Dense Labels from CLIP.” European Conference on Computer Vision (ECCV). 2022. ↩︎