pu239's page
about me
publications
projects
other stuff
Home
»
Tags
CLIP
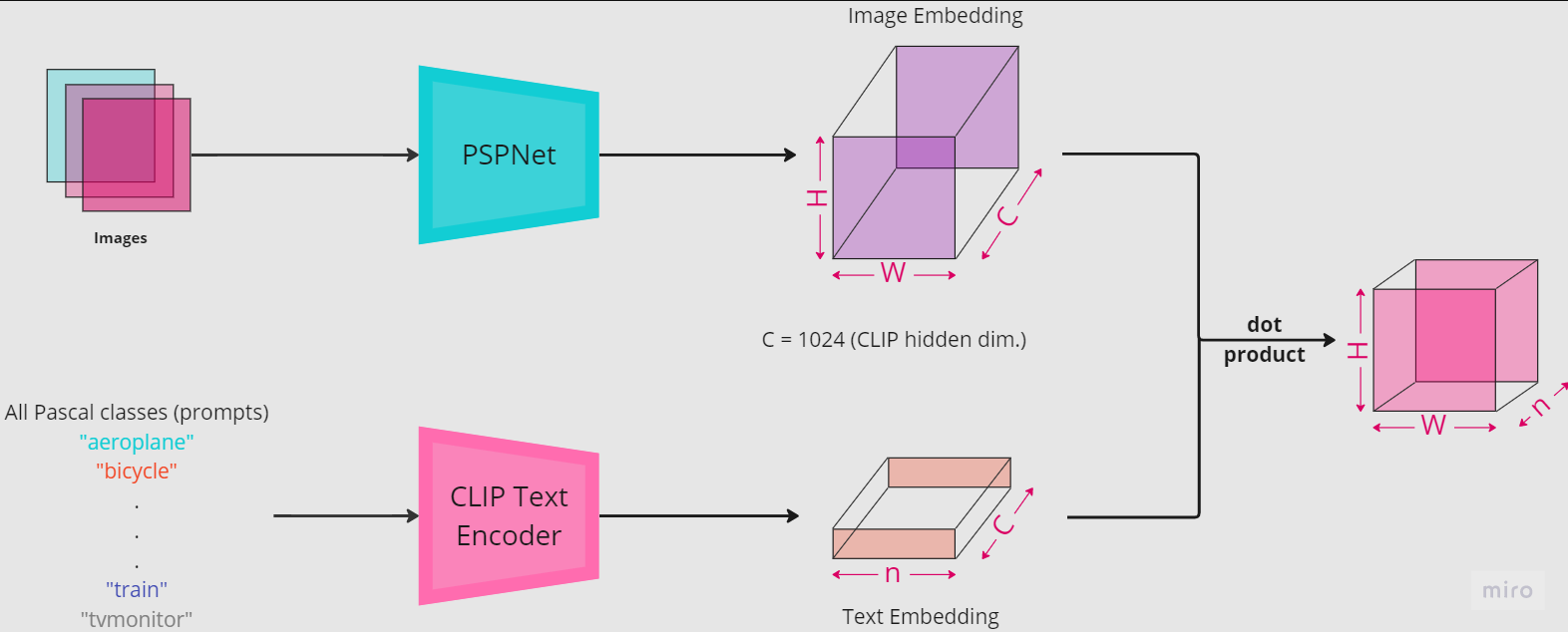
Segmentation using CLIP
...